TVM 在 GPU 上的优化
概览
在GPU上TVM主要针对卷积(convolution)操作进行了优化,在此演示探讨中:
- 假设卷积输入有较大批量
- 使用不同的布局来存储数据,以获得更好的数据局部性
算法
我们使用256通道与14 x 14维的固定大小的张量,且每批处理的样本的个数为256。卷积滤波器包含512个大小为3 x 3的滤波器,使用步长1和填充大小1进行卷积。TVM代码如下:
import numpy as np
import tvm
# The sizes of inputs and filters
batch = 256
in_channel = 256
out_channel = 512
in_size = 14
kernel = 3
pad = 1
stride = 1
# Algorithm
A = tvm.placeholder((in_size, in_size, in_channel, batch), name='A')
W = tvm.placeholder((kernel, kernel, in_channel, out_channel), name='W')
out_size = (in_size - kernel + 2*pad) // stride + 1
# Pad input
Apad = tvm.compute(
(in_size + 2*pad, in_size + 2*pad, in_channel, batch),
lambda yy, xx, cc, nn: tvm.select(
tvm.all(yy >= pad, yy - pad < in_size,
xx >= pad, xx - pad < in_size),
A[yy - pad, xx - pad, cc, nn], tvm.const(0.)),
name='Apad')
# Create reduction variables
rc = tvm.reduce_axis((0, in_channel), name='rc')
ry = tvm.reduce_axis((0, kernel), name='ry')
rx = tvm.reduce_axis((0, kernel), name='rx')
# Compute the convolution
B = tvm.compute(
(out_size, out_size, out_channel, batch),
lambda yy, xx, ff, nn: tvm.sum(
Apad[yy * stride + ry, xx * stride + rx, rc, nn] * W[ry, rx, rc, ff],
axis=[ry, rx, rc]),
name='B')
显存结构
首先,我们先介绍GPU的显存层次结构。下图显示了GPU的显存结构,从图中我们发现与内存一个显著的差异是,GPU提供一个叫做Shared Memory的Cache,故而如何充分实现Shared Memory中的数据重用是提高GPU计算性能的关键之一。

举一个例子,我们将Apad与W存入缓冲AA与缓冲WW中,并放入Shared Memory中。这些缓冲会被该线程块所有计算任务所使用,每个线程从该缓冲调取自己计算所需数据。
# Designate the memory hierarchy
s = tvm.create_schedule(B.op)
s[Apad].compute_inline() # compute Apad inline
AA = s.cache_read(Apad, 'shared', [B])
WW = s.cache_read(W, "shared", [B])
AL = s.cache_read(AA, "local", [B])
WL = s.cache_read(WW, "local", [B])
BL = s.cache_write(B, "local")
分块
考虑到显存并不总是充足到加载所有数据,矩阵乘的分块策略不失为一种很好的方式。
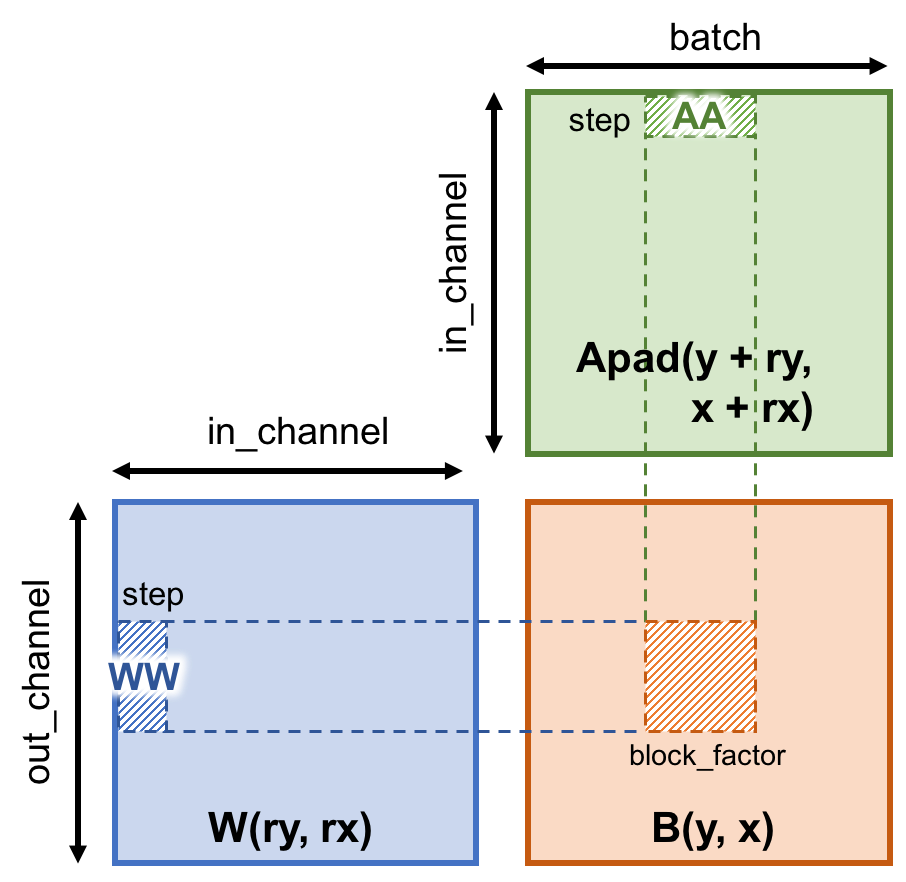
# tile consts
tile = 8
num_thread = 8
block_factor = tile * num_thread
step = 8
vthread = 2
# Get the GPU thread indices
block_x = tvm.thread_axis("blockIdx.x")
block_y = tvm.thread_axis("blockIdx.y")
block_z = tvm.thread_axis("blockIdx.z")
thread_x = tvm.thread_axis((0, num_thread), "threadIdx.x")
thread_y = tvm.thread_axis((0, num_thread), "threadIdx.y")
thread_xz = tvm.thread_axis((0, vthread), "vthread", name="vx")
thread_yz = tvm.thread_axis((0, vthread), "vthread", name="vy")
# Split the workloads
hi, wi, fi, ni = s[B].op.axis
bz = s[B].fuse(hi, wi)
by, fi = s[B].split(fi, factor=block_factor)
bx, ni = s[B].split(ni, factor=block_factor)
# Bind the iteration variables to GPU thread indices
s[B].bind(bz, block_z)
s[B].bind(by, block_y)
s[B].bind(bx, block_x)
虚拟线程拆分
进一步的,将线程块分给不同的线程计算。为了避免“memory bank conflict”,利用虚拟线程将此block分为四部分,见下图与代码。
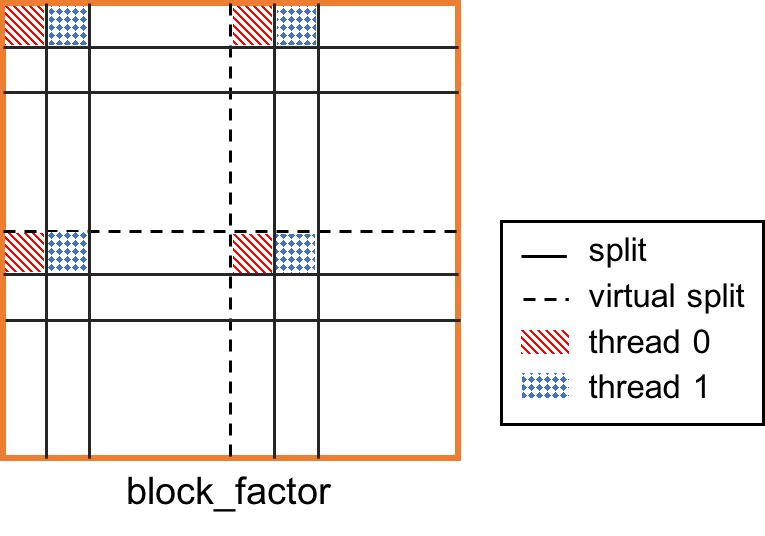
tyz, fi = s[B].split(fi, nparts=vthread) # virtual thread split
txz, ni = s[B].split(ni, nparts=vthread) # virtual thread split
ty, fi = s[B].split(fi, nparts=num_thread)
tx, ni = s[B].split(ni, nparts=num_thread)
s[B].reorder(bz, by, bx, tyz, txz, ty, tx, fi, ni)
s[B].bind(tyz, thread_yz)
s[B].bind(txz, thread_xz)
s[B].bind(ty, thread_y)
s[B].bind(tx, thread_x)
合作读取
为了减少每个线程间的数据传输,下面的代码让同一个线程块中的线程合作读取全局显存中的相关数据。
# Schedule BL local write
s[BL].compute_at(s[B], tx)
yi, xi, fi, ni = s[BL].op.axis
ry, rx, rc = s[BL].op.reduce_axis
rco, rci = s[BL].split(rc, factor=step)
s[BL].reorder(rco, ry, rx, rci, fi, ni)
# Attach computation to iteration variables
s[AA].compute_at(s[BL], rx)
s[WW].compute_at(s[BL], rx)
s[AL].compute_at(s[BL], rci)
s[WL].compute_at(s[BL], rci)
# Schedule for A's shared memory load
yi, xi, ci, ni = s[AA].op.axis
ty, ci = s[AA].split(ci, nparts=num_thread)
tx, ni = s[AA].split(ni, nparts=num_thread)
_, ni = s[AA].split(ni, factor=4)
s[AA].reorder(ty, tx, yi, xi, ci, ni)
s[AA].bind(ty, thread_y)
s[AA].bind(tx, thread_x)
s[AA].vectorize(ni) # vectorize memory load
# Schedule for W's shared memory load
yi, xi, ci, fi = s[WW].op.axis
ty, ci = s[WW].split(ci, nparts=num_thread)
tx, fi = s[WW].split(fi, nparts=num_thread)
_, fi = s[WW].split(fi, factor=4)
s[WW].reorder(ty, tx, yi, xi, ci, fi)
s[WW].bind(ty, thread_y)
s[WW].bind(tx, thread_x)
s[WW].vectorize(fi) # vectorize memory load
生成CUDA核
最后用TVM生成CUDA核,代码如下。
func = tvm.build(s, [A, W, B], 'cuda')
ctx = tvm.gpu(0)
a_np = np.random.uniform(size=(in_size, in_size, in_channel, batch)).astype(A.dtype)
w_np = np.random.uniform(size=(kernel, kernel, in_channel, out_channel)).astype(W.dtype)
a = tvm.nd.array(a_np, ctx)
w = tvm.nd.array(w_np, ctx)
b = tvm.nd.array(np.zeros((out_size, out_size, out_channel, batch), dtype=B.dtype), ctx)
func(a, w, b)
evaluator = func.time_evaluator(func.entry_name, ctx, number=1)
print('Convolution: %f ms' % (evaluator(a, w, b).mean * 1e3))