NNVM 编译器综合简介
NNVM 编译器的由来
近些年随着深度学习的火热发展,各种各样的框架层出不穷。深度学习之所以能够火热发展,首先的一个原因是数据量积累足够大并且计算设备计算资源、计算能力的大幅度提升,另一方面,深度学习能够在众多领域上快速铺开,也得益于它的灵活性,因为深度学习相比传统机器学习来说,可以具备更多样的输入和输出,模型设计也可以非常灵活。这样的灵巧性必然导致了深度学习框架前端用户接口的多样化,在这一层面上,深度学习可以理解为是一种语言,每种框架提供了深度学习不同的前端接口,因此,深度学习的前端也很有可能向编程语言那样,风潮涌动。
另一方面,深度学习应用需要大量的计算,而就目前,甚至未来几年内也很难有单一的硬件架构解决所有需求,所以必然导致不同场景的问题可能选择不同的硬件。如 GPU 适合模型训练,CPU 由于大量存在也经常作用于云端模型预测,FPGA、ARM 等也逐渐加入到深度学习的硬件计算资源中来。
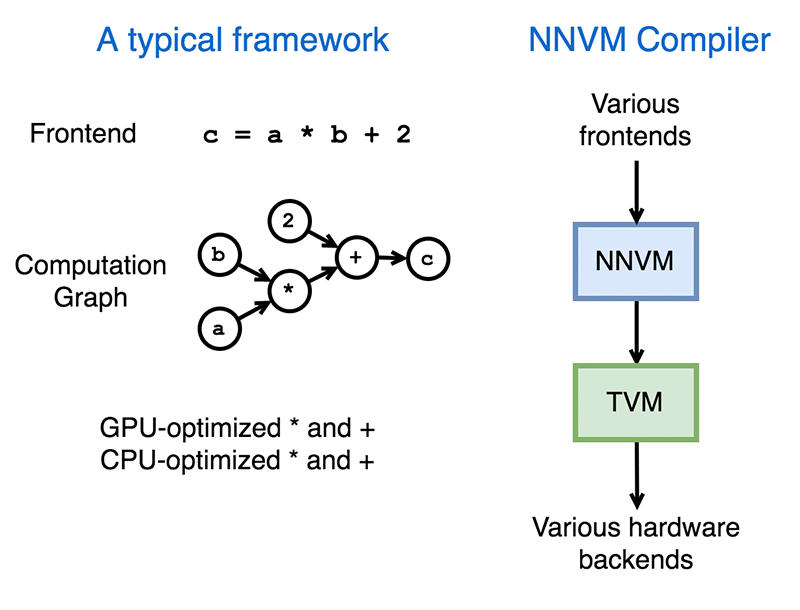
基于以上两点问题,回顾历史,便会发现当年编程语言也面临这这样的问题:编程语言层出不穷,CPU 架构不断翻新。 在那个时期里,LLVM 横空出世,通过很好的模块化分离前端和后端,为新的语言和新的硬件提供非常友好的支持。
因此 NNVM 编译器提出的基本思想与 LLVM 相当接近,目的也是为了给新出现的框架和硬件提供友好的支持。
NNVM 编译器用途
基于 NNVM 编译器的设计思想,下图给出了 NNVM 编译器的工作原理。
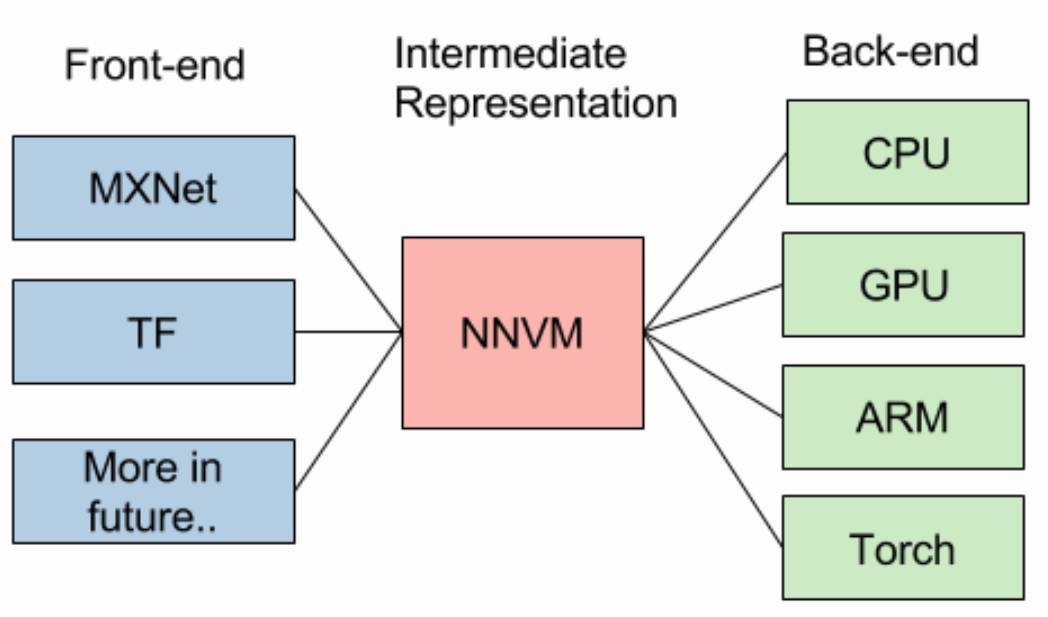
目前大多数深度学习框架(如 Tensorflow, MXNet 等)均采用了计算图的形式来表示一个深度学习模型,在 NNVM 中,前端作为不同的深度学习框架的计算图,这些计算图输入给 NNVM 后,通过 NNVM 将计算图做统一的转换,再根据目标资源(如 CPU,GPU,ARM 等)的特性对计算图做出必要的操作和优化,最后输出到对应计算资源的硬件代码。
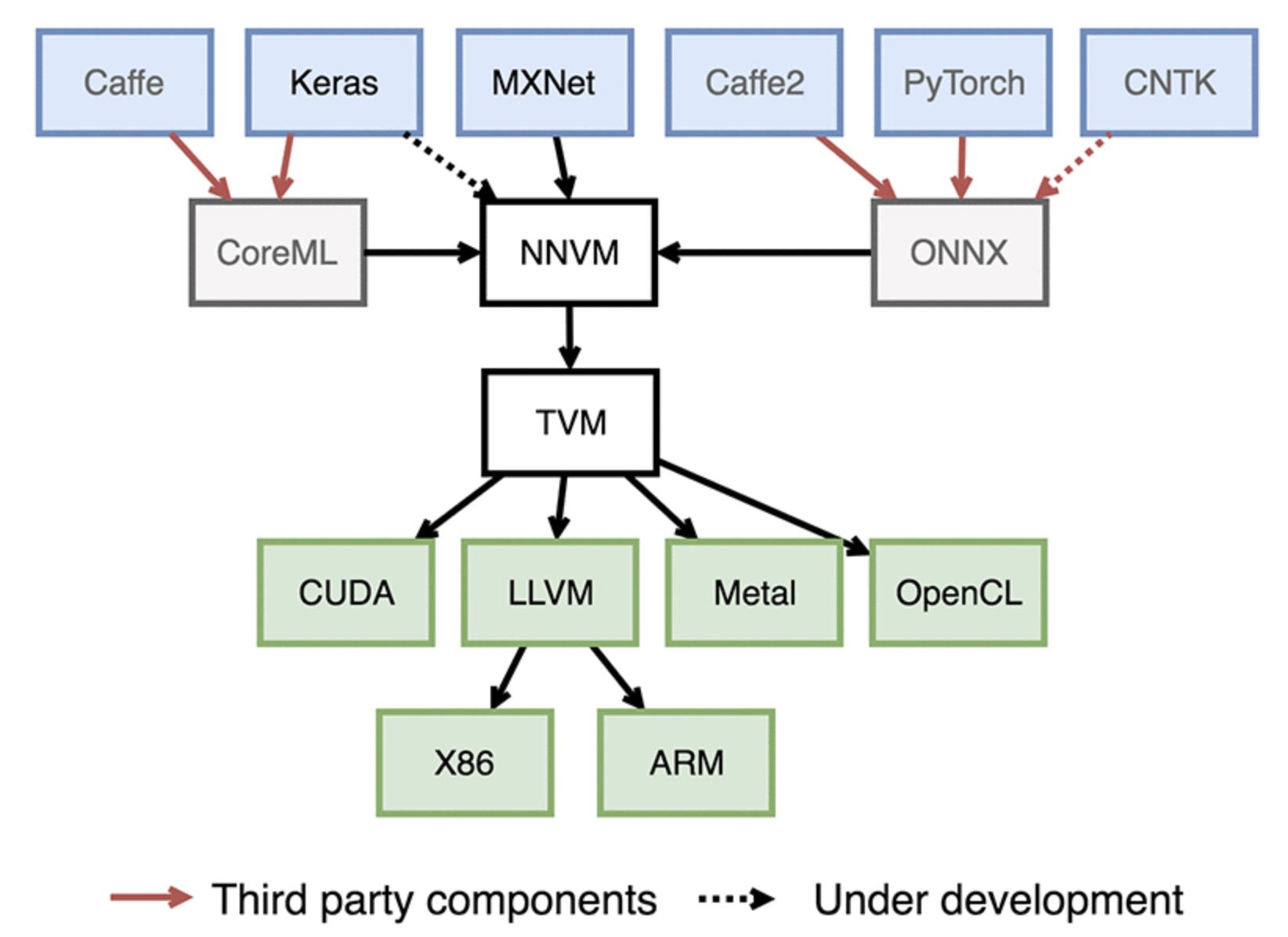
NNVM 架构及流程
下图给出了 NNVM 编译器的基本架构。
从上图可以看出,NNVM 编译器中主要有两个部件组成,第一个是 NNVM (注:本篇报告以下内容如果没有特别说明时 NNVM 编译器,所提到的 NNVM 均指此处的 “狭义” NNVM),第二个是 TVM。
NNVM 通过将来自不同的框架的工作负载表示成标准的计算图,然后将这些图翻译成执行图。 NNVM 同时还搭配了称作 Pass 的例程,以操作这些计算图。这些例程要么往图上添加新的属性以执行他们,要么调整图以提高效率。
TVM 起源于 Halide,用于在计算图中实现算子,并对其进行优化用于目标后端硬件。 和 NNVM 不同,它提供了一个硬件无关的、领域特定的语言以在张量指标级上简化算子实现。TVM 还提供了调度原语比如多线程、 平铺和缓存以优化计算,从而充分利用硬件资源。这些调度是硬件相关的,要么用手工编写,要么也可以自动搜索优化模式。