TVM:Tensor IR Stack for Deep Learning Systems
1. 概述
TVM是一种将深度学习工作负载部署到硬件的端到端IR(中间表示)堆栈。亦即为一种把深度学习模型分发到各种硬件设备上的、端到端的解决方案。
TVM编译器可以:
- 把模型部署到不同硬件,例如Nvidia GPU、AMD GPU、FPGA等
- 支持比较方便的自动调优和轻量级部署
- 提供从现有前端框架到裸机硬件的端到端编译
TVM尝试从更高的抽象层次上总结深度学习op的手工优化经验,用来使得用户可以快速地以自动或者半自动的方法探索高效的op实现空间。
2. 特点
支持的不同后端与硬件
TVM堆栈的目标,是提供一个可重复使用的工具链,来将高级神经网络描述从深度学习框架前端,向下编译为多个硬件后端的低级机器代码。难点在于支持多个硬件后端,同时将计算、内存和能量足迹保持在最低水平。通过借鉴了编译器界其他的案例,dlmc团队构建了两级中间层:其中一层是NNVM(用于任务调度和内存管理的高级中间表示),另一层是TVM(用于优化计算内核的富有表现力的低级中间表示)。
然而,仅基于IR的计算图(NNVM)不足以解决支持不同硬件后端的挑战。因为单独一个图形运算符,例如卷积或矩阵乘法能以非常不同的方式映射和优化在不同的硬件后端。这些特定硬件优化在内存布局、并行线程模式、缓存访问模式和硬件基元的选择方面,可能会发生巨大的变化。故建立了一个低级表示(TVM)来解决这个问题。这个表示基于索引公式,而且支持重复计算。
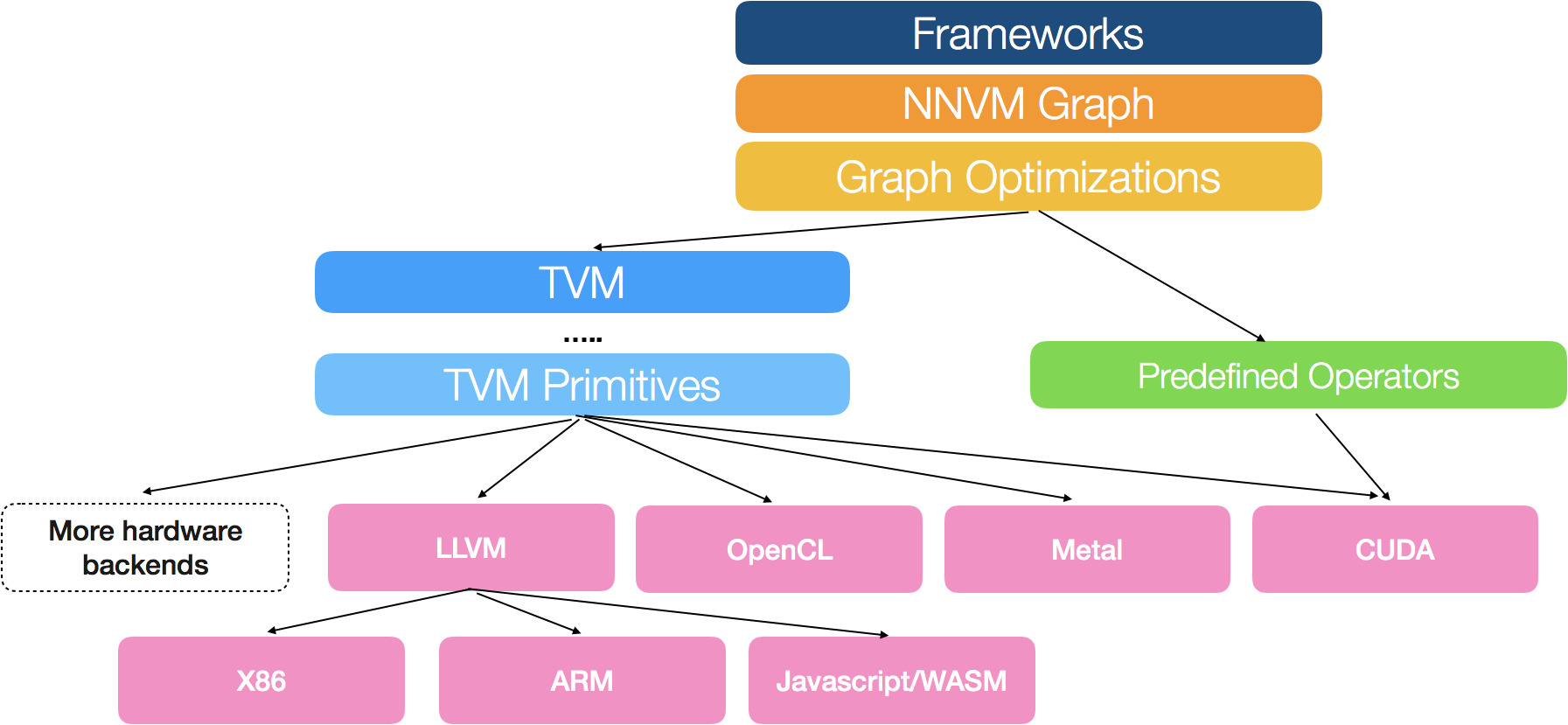
轻量级部署
TVM的优势之一,就是对多个平台和语言提供了丰富的支持。这由两个部分组成。一是编译器堆栈,其中包括完整的优化库,以产生优化过的机器代码;二是轻量级的运行环境,提供了在不同平台上部署编译模块所需的可移植性。
TVM目前支持嵌入式编译器堆栈的Python和C++接口。在设计框架时最大程度的实现了重复利用,以便编译器堆栈的改进可以在Python和C++组建之间互换使用。
TVM提供了一个轻量级的运行环境,可以让TVM用JavaScript、Java、Python、C++等编译过的代码,运行在Android、iOS、树莓派和网页浏览器等平台上。
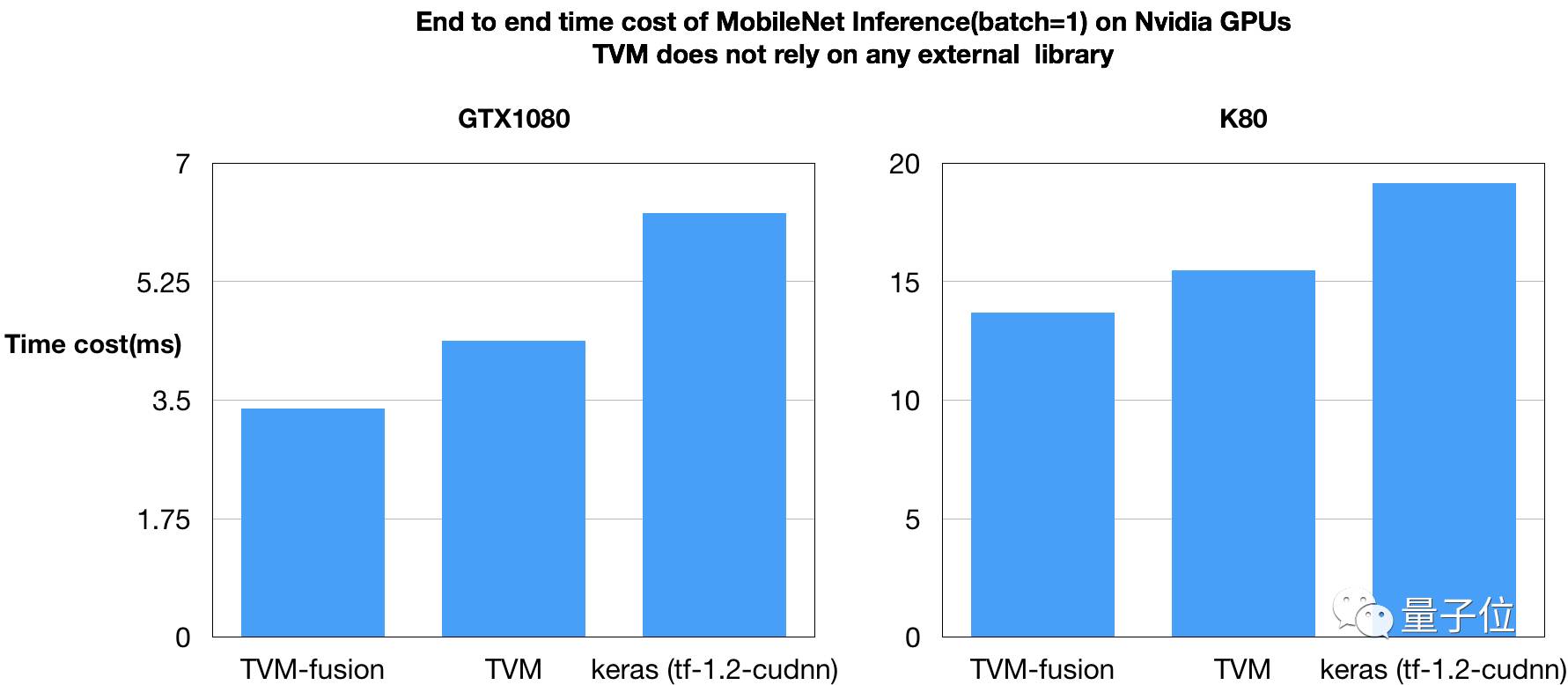
3. 性能
Nvidia GPU
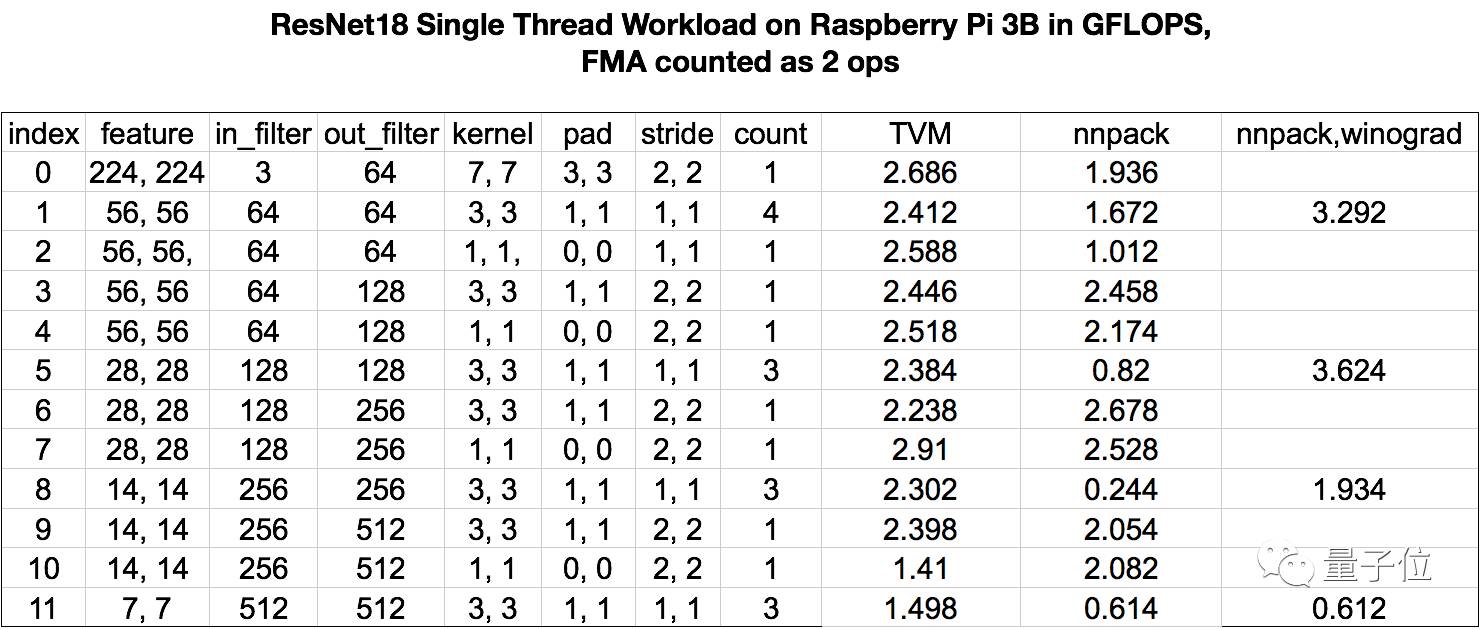
Raspberry Pi 3b
4. 对比
TVM和已有的解决方案不同,以XLA作为例子,TVM走了和目前的XLA比更加激进的技术路线,tvm可以用来使得实现XLA需要的功能更加容易:已有的解决方案本身基于高级图表示的规则变换,可以产生一些图级别的组合op优化,如conv-bn fusion,但是依然要依赖于手写规则来达到从图的表示到代码这一步。图的op表示到代码本身可以选择的东西太多,如何做线程,如何利用shared memory,而大部分没有在图语言里面得到刻画,导致难以自动化。 这样下去深度学习系统的瓶颈必然从op实现的复杂度变成了实现graph compiler中模式生成规则的复杂度。
故TVM采取了风险更大但是回报也更大的长远技术路线。简单地说,TVM通过把图到op生成规则这一步进一步抽象化,把生成规则本身分成各个操作原语,在需要的时候加以组合。基于tvm,可以快速地组合出不同的schedule方案。